5th Annual Conference on Teaching & Learning: Learning Technologies
A month ago, together with Jacek Jankowski and Filip Czaja, we wrote an abstract for 5th Annual Conference on Teaching & Learning: Learning Technologies. Recently, we have been asked to present the abstract on the conference, in the beginning of June.
Below, there is the abstract:
…Adapting informal sources of knowledge to e-Learning.
The amount of information sources and the
Submission for ISWC ’07
Today we submitted yet another article; this time for The 6th International Semantic Web Conference (ISWC ’07) that will take place in Busan, Korea, from November 11 to 15 (Thursday), 2007. I was the main author of the paper; i wrote it together with Sebastian R. Kruk, Tadhg Nagle, Edward Curry, and Adam Gzella. Its title is “IKHarvester – Informal …
Summary of our work in DERI
In less than two weeks I’m living DERI. I’m going back home in Poland. The plan is to defend my Master’s Thesis.
Before leaving, we (myself, Filip Czaja and Władysław Bultrowicz) are supposed to present the result of our work. We gave the presentation today.
First, Filip introduced ourselves and showed the context of our work:
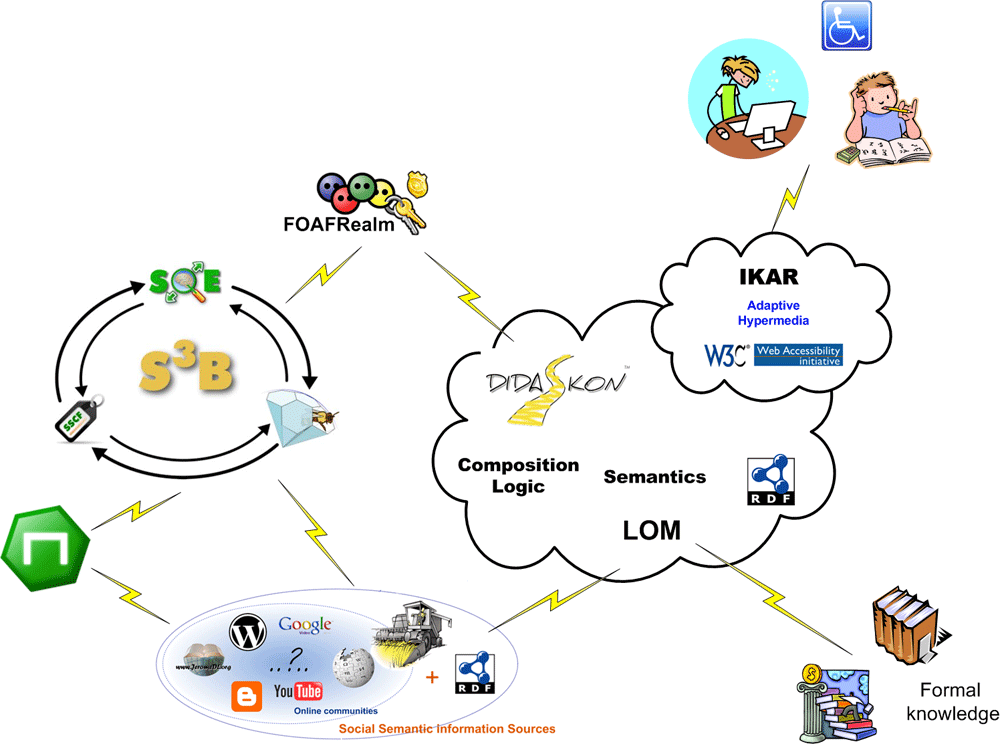
Then there was my …
IKHarvester
Some time ago I wrote about Didaskon, a framework for composing curriculum for a specific user, basing on his profile and using formal and informal knowledge. I belong to team of the developers.
At the moment, I am developing the one of its component – IKHarvester (Informal Knowledge Harvester). It aims at collecting (harvesting) data from Social Semantic Information Sources …
Didaskon
Here is some information taken from my Master’s Thesis (still developed)..
Didaskon is a project developed in Digital Enterprise Research Institute (DERI), Ireland by a few students, including myself. It is a research project in the elearning field. Its main goal is to deliver a framework for assemblying an ondemand curriculum from existing Learning Objects (LOs) provided by e-Learning services.…
IKHarvester_2
Remember my previous post about IKHarvester. There, I’ve briefly described how I collect metadata for blog posts which support SIOC. Then, I thought it’s a good idea to describe in one place what really IKHarvester is and how it works.
IKHarvester (Informal Knowledge Harvester) is a web service that characterizes with two core features: harvesting data, and providing it for …
Slides on eLearning and SSIS
As you’ve probably noticed, quite a few posts on my blog are directly related to eLearning, the Semantic Web, and Web 2.0. Yet, “Social Semantic Information Sources for eLearning” is the topic of my Master’s Thesis. This is the main area for the research I do in the Digital Enterprise Research Institute (DERI).
I’ve already mentioned of two my (and …
notitio.us project
Recently, the SemInf group, which member I am, from DERI eLearning Cluster has set up new project: notitio.us.
Notitio.us is service for collaborative knowledge aggregation and sharing. It employs IKHarvester for retrieving RDF information about Web resources bookmarked by the users. Therefore, it is capable of indexing rich metadata, coming from various types of resources.
In contrary to bookmarking services, …
Sumbission for EC-TEL ’07 accepted
Some time ago, myself together with Sebastian R. Kruk, Adam Gzella, Bill McDaniel, and Tomasz Woroniecki wrote an article for EC-TEL 2007 – Second European Conference on Technology Enhanced Learning that will take place in Semptember in Creete, Greece.
The title of the article is “E-Learning on the Social Semantic Information Sources”. In general, it relates to eLearning, Semantic …
Some scientific actions
A few months ago, myself along with friends, wrote an article to the ICWSM ’06 conference which should have take place in Boukder, USA. The titke of the article was: “E-Learning on the Social Semantic Information Sources”. We wrote quite a few pages but the paper was rejected ![]() The reviewers stated it was quite good, but needed to be …
The reviewers stated it was quite good, but needed to be …
- 1
- 2